I am a Research Scientist at Apple Machine Learning Research (MLR) working on building generalist interactive and embodied AI systems that will enable humans to be more productive and creative. Towards, that I am interested in imbuing agents with the ability to perceive their surroundings, reason about them, and take actions to accomplish their goals.
Some representative projects towards this goal are:
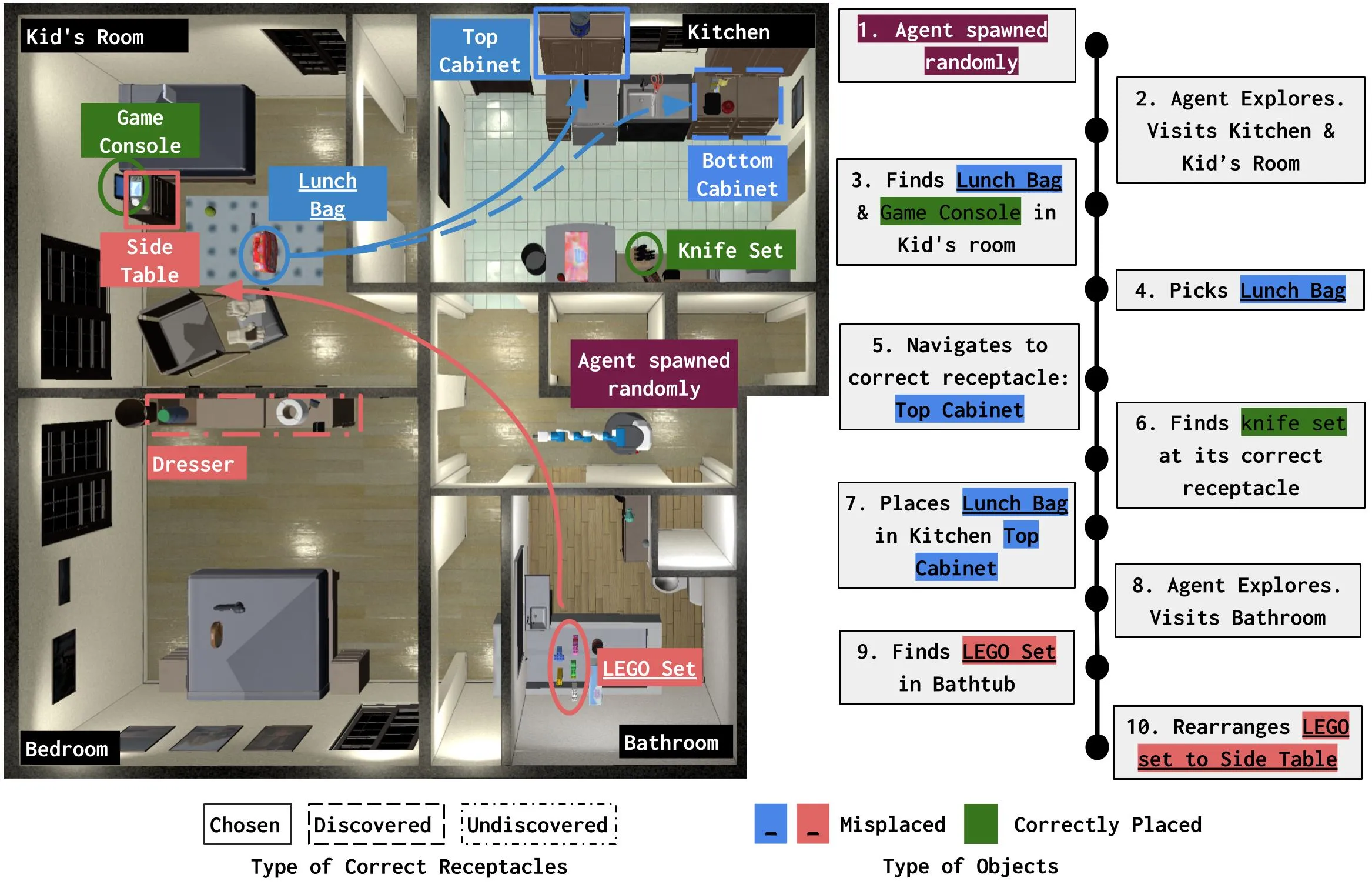
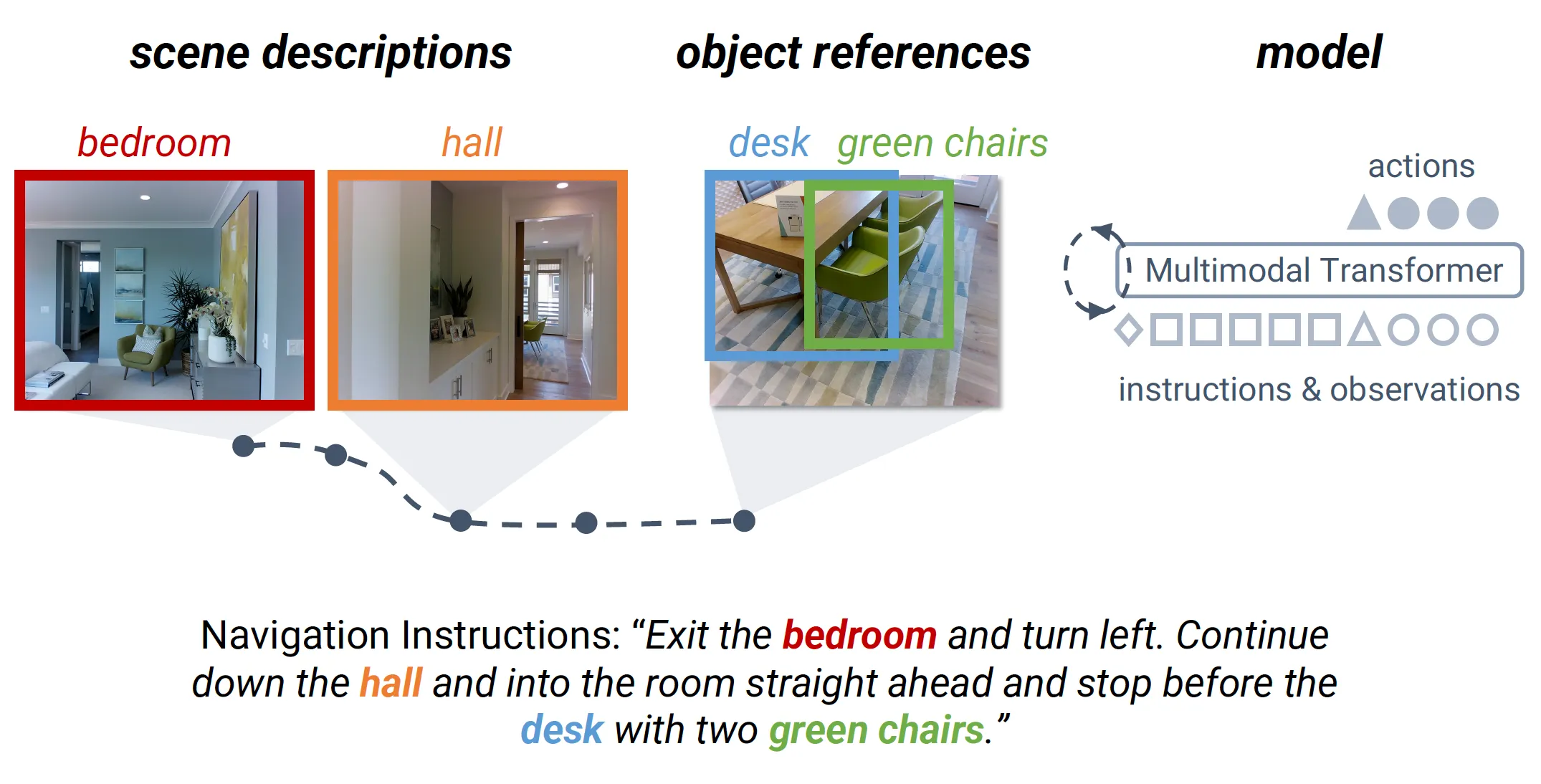
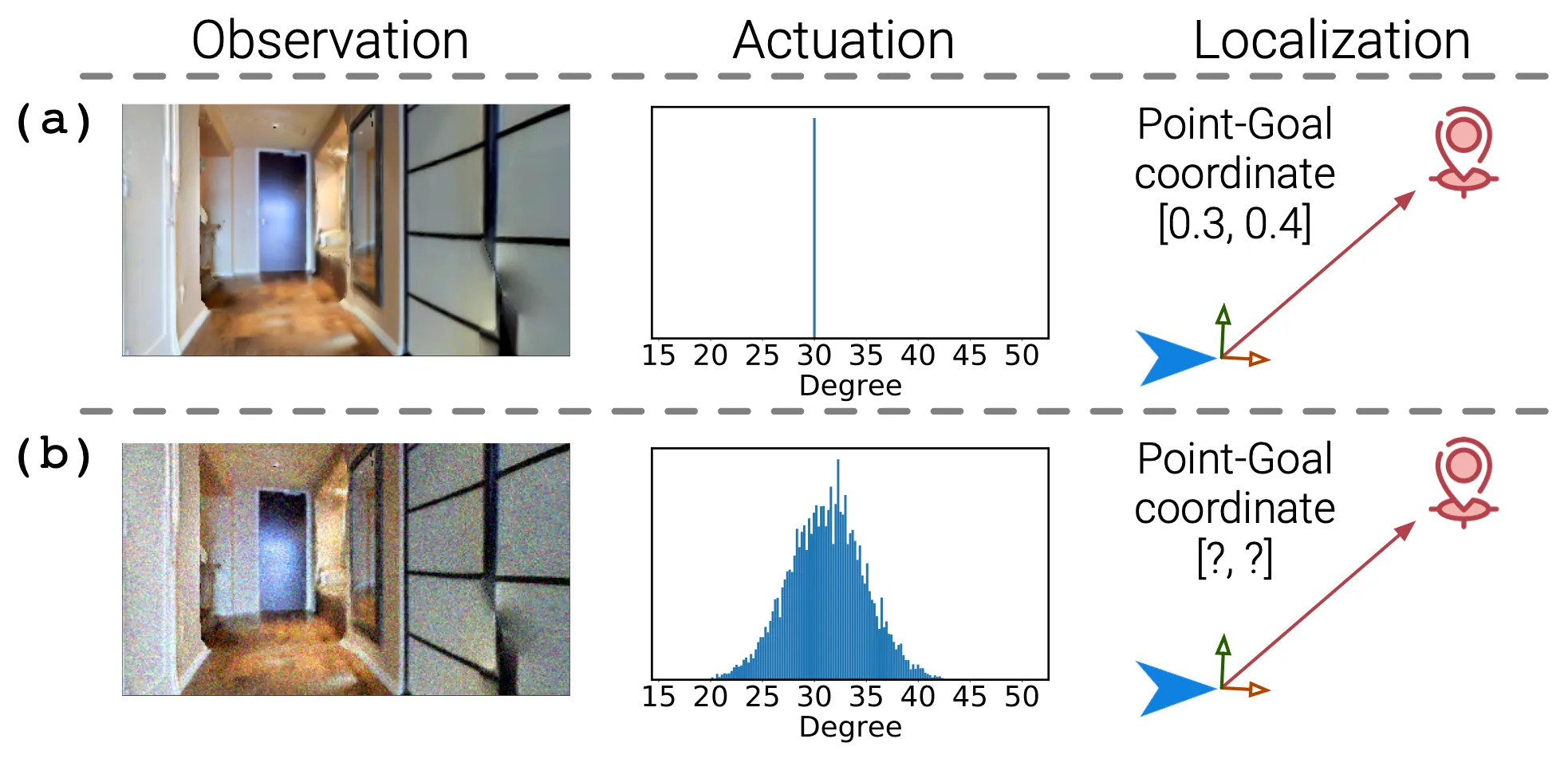
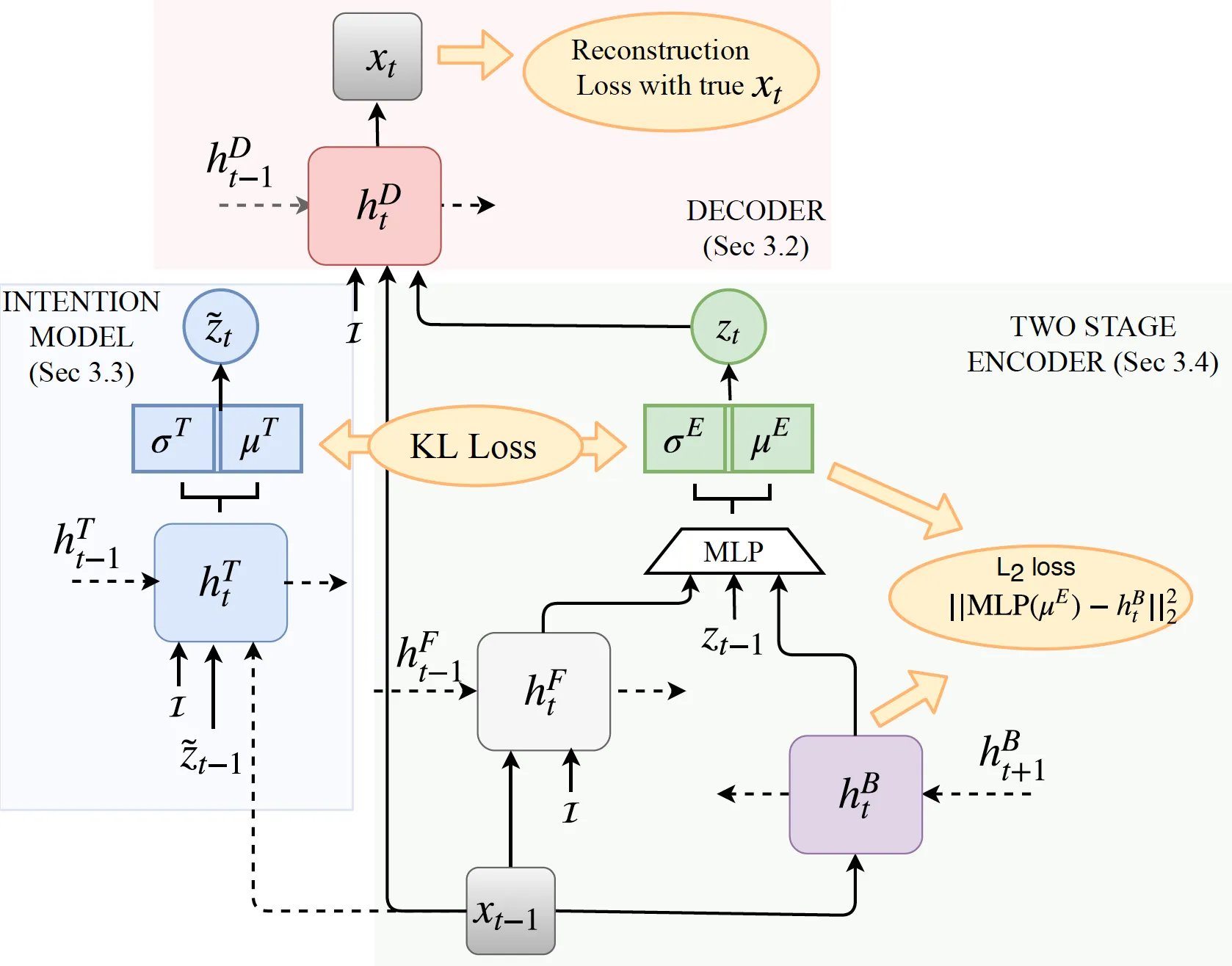
- Embodied Agents: , Language-guided Navigation Agents, Robust Indoor Navigation Models
- Digital Agents: Universal UI Understanding,
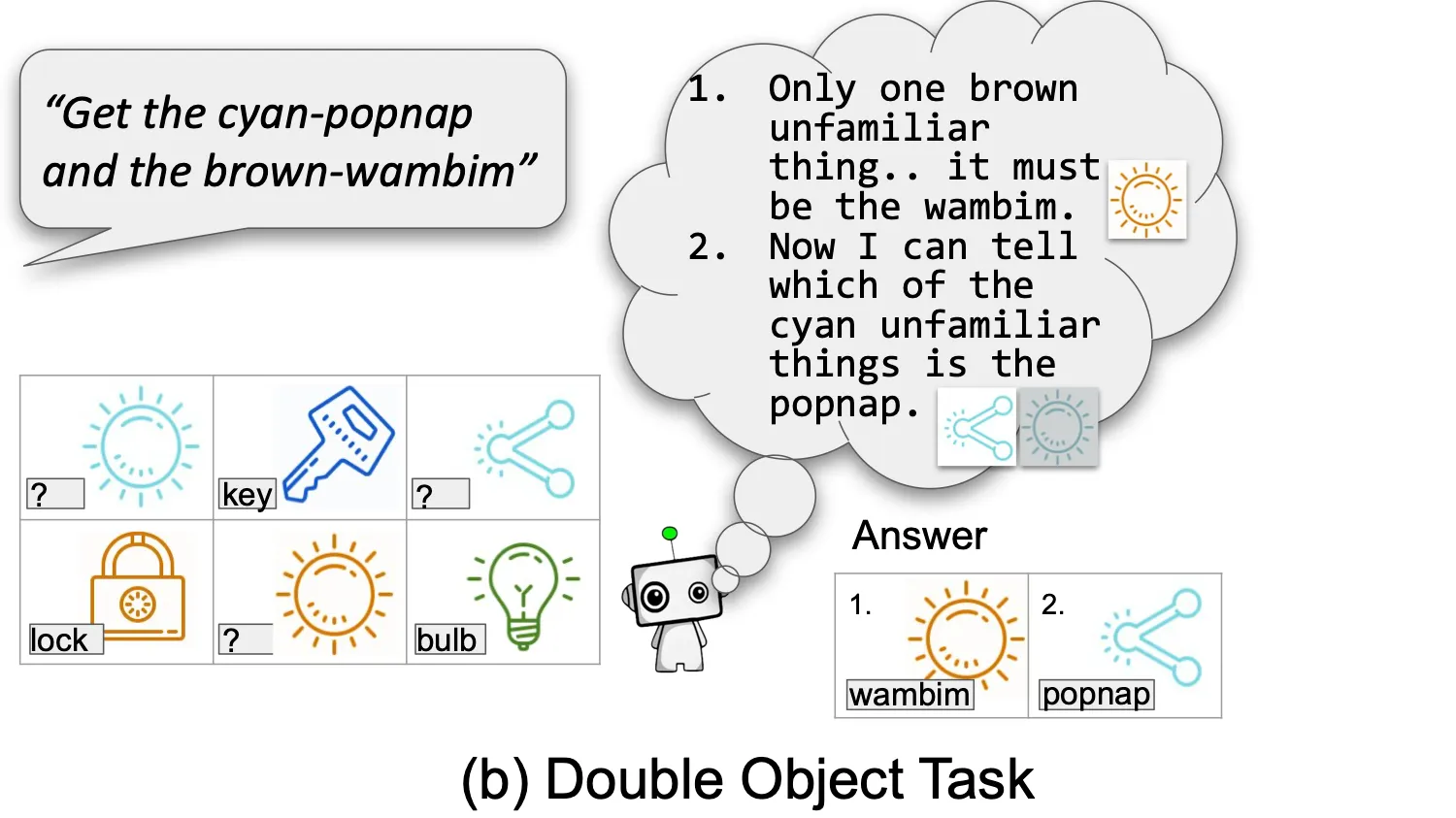
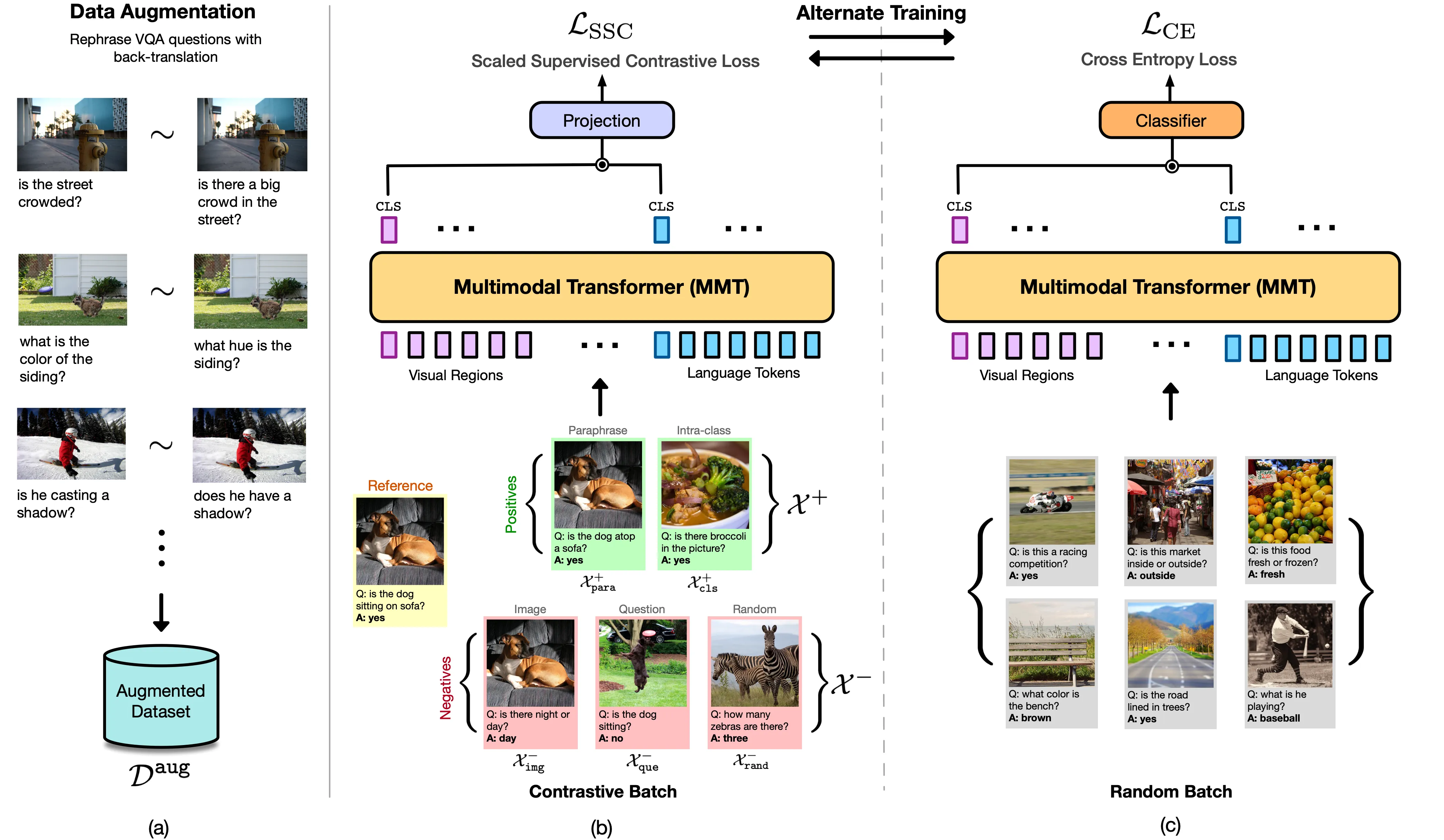
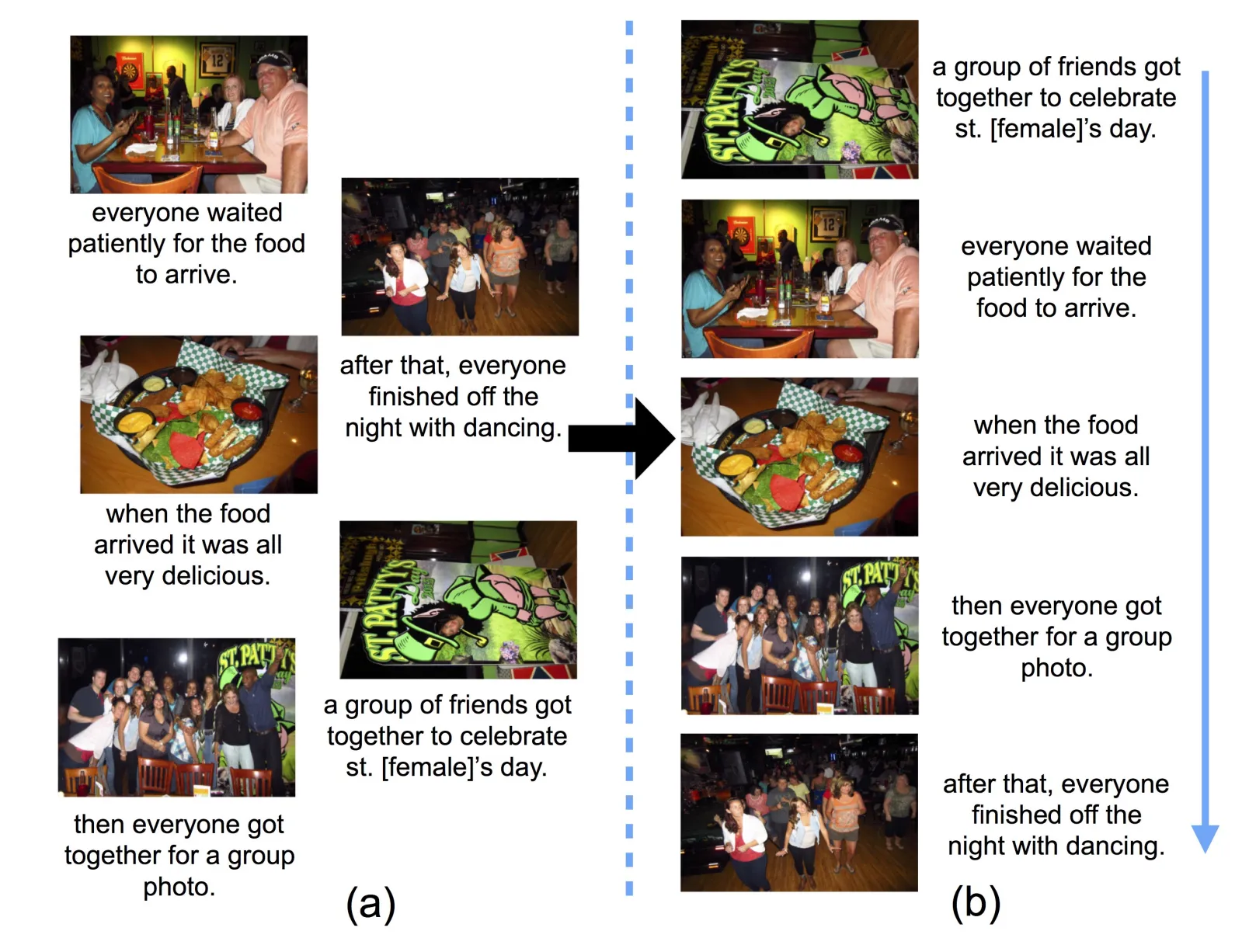
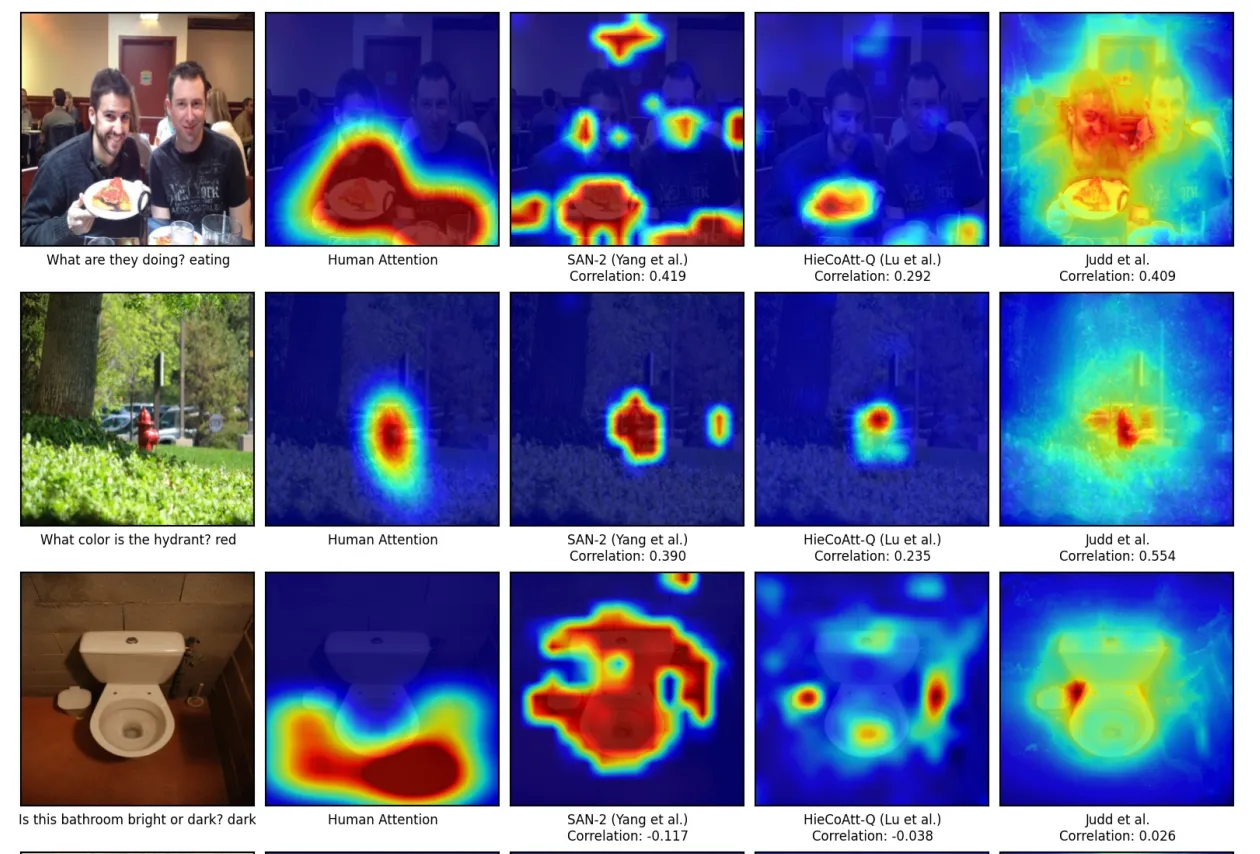
- Vision & Language: Novel Object Captioning, Visual Question Answering, Human vs Machine Attention,
I received my PhD at Georgia Tech advised by Dhruv Batra in 2023. My PhD was partially supported by the Snap Fellowship 2019 . I also collaborated with Devi Parikh (Georgia Tech), Natasha Jaques (Google Brain), Peter Anderson (Google Research), Gal Chechik (NVIDIA), Marcus Rohrbach (Facebook AI Research), and Alex Schwing (UIUC). Before my PhD, I spent a couple of years as a Research Engineer at Snap Research where I was responsible for building large-scale infrastructure for visual recognition, search and developed algorithms for low-shot instance detection.
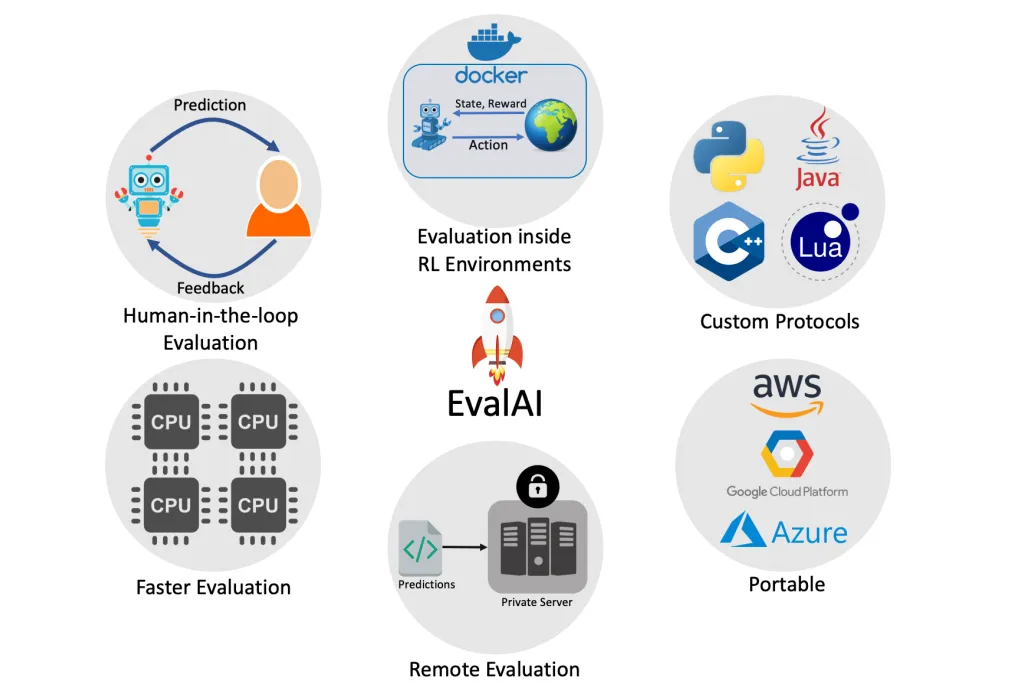
Aside from research, I helped maintain and manage an AI challenge hosting platform called EvalAI to make AI research more reproducible. EvalAI hosts 150+ challenges and has 300+ contributors, 2M+ annual pageviews, 1400+ forks, 4500+ solved issues and merged pull requests, 3000+ 'stars' on Github.









 Code
Code