Scenes: We use a manually-selected subset of 55 photorealistic scans of indoor environments from the
Gibson dataset.
These 55 scenes are uncluttered ‘empty’ apartments/houses, i.e. they contain no or very few furniture as part
of the scanned mesh. Scanned object meshes are programmatically inserted into these scenes to create episodes.
This combination of empty houses and inserted objects allows
for controlled generation of training and testing episodes.
Objects: We use object scans from the YCB Dataset. These objects are small enough that they can pass
through doors
and hallways within the house.
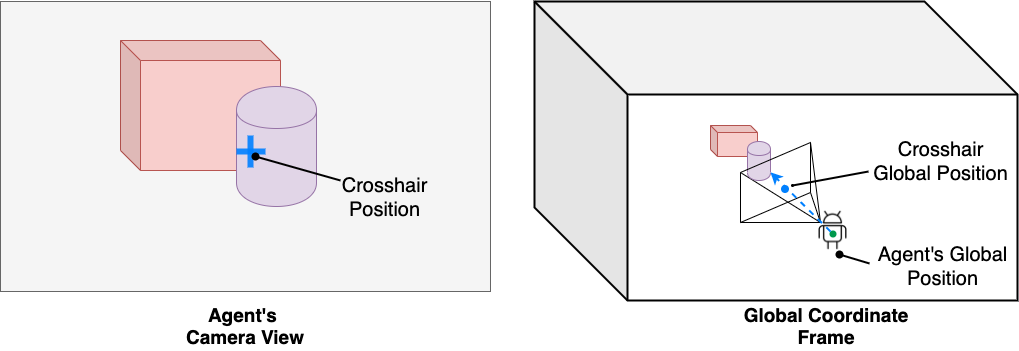
Episodes: As illustrated in Figure 1, each episode requires the agent to rearrange
2-5 objects. At the beginning of each episode, the agent is provided with the goal location and rotation
of each object via point-coordinates (3D coordinate of the center of mass of the object). The agent is also
given the spawn location and rotation of the agent, initial object location, rotation, and type in the
environment.
Finally, for each object, the episode defines goal location and rotation for each object’s centre-of-mass (COM).
{�
'episode_id': 0,�
'scene_id': 'data/scene_datasets/coda/coda.glb’,�
'start_position': [-0.15, 0.18, 0.29],�
'start_rotation': [-0.0, -0.34, -0.0, 0.93]�
'objects’: [
{�
'object_id': 0,�
'object_template': 'data/test_assets/objects/chair',�
'position': [1.77, 0.67, -1.99],�
'rotation': [0.0, 0.0, 0.0, 1.0]�
}
],
'goals’: [
{�
'position': [4.34, 0.67, -5.06],�
'rotation': [0.0, 0.0, 0.0, 1.0]�
}
],�
}